All of that can be handled with a special cookie(s) which will flag different scenarios but in my experience this is a clumsy solution. You will need to think of all possible user journeys and make sure that appropriate cookies are created. Caching is very difficult on it’s own so there is no need to make it even more complicated. Much better approach in my opinion is pulling data directly from a PHP session.
PHP by default stores session in a file. This might be OK with a single server architecture but if you have more than one web server than you need a centralised storage. Independently of your setup much better place for a PHP session is memcached. It will improve access time, scalability and of course – you will be able to access session from Varnish.
Storing session data inside the memcached is very simple to do with PHP.
$ sudo apt-get install memcached php5-memcached $ sudo /etc/init.d/memcached start
Edit the php.ini file.
$ sudo vim /etc/php5/apache2/php.ini
Look for session settings
[Session] ; Handler used to store/retrieve data. ; http://php.net/session.save-handler session.save_handler = files
and change it to
[Session] ; Handler used to store/retrieve data. ; http://php.net/session.save-handler session.save_handler = memcached session.save_path = "localhost:11211"
Now restart apache and it’s done.
$ sudo /etc/init.d/apache2 restart
If you like you can test it with the below code.
addServer('localhost', 11211);
foreach( $m->getAllKeys() as $key ) {
printf( '%s
', $key );
var_dump ( $m->get( $key ) );
}
It should return something like this:
memc.sess.key.lock.78uso0onvumb665c1gm739er36 string '1' (length=1) memc.sess.key.78uso0onvumb665c1gm739er36 string 'test|s:11:"Hello World";' (length=24)
If it’s all working lets create a simple page which will simulate multilingual support.
<?php
session_start();
if( isset( $_POST['lang'] ) ) {
print_r($_POST);
$_SESSION['lang'] = $_POST['lang'];
}
$lang = isset( $_SESSION['lang'] ) ? $_SESSION['lang'] : 'English';
printf( "My language is: %s (%s)
", $lang, time() );
?>
- English
- Spanish
- German
The idea is simple. If langues is set PHP will store it in session as “lang” and appropriate content will be displayed.
The challenge for Varnish is to create and return an appropriate cache based on selected language. Language is saved as a serialised string inside the memcached. It’s stored under “memc.sess.key.UNIQUE_KEY” where the UNIQUE_KEY is a value from the PHPSESSID cookie.
To access memcached from Varnish Cache script you have to install VMOD-Memcached. To compile this module you need Varnish source code.
$ wget http://repo.varnish-cache.org/source/varnish-3.0.3.tar.gz $ tar zxfv varnish-3.0.3.tar.gz
Get the VMOD and all dependencies.
$ git clone https://github.com/sodabrew/libvmod-memcached $ sudo apt-get install libmemcached-dev python-docutils $ cd libvmod-memcached $ ./autogen.sh $ ./configure VARNISHSRC=../varnish-3.0.3/ $ make $ sudo make install
The extension should be copied into your Varnish vmod directory.
$ ls /usr/local/lib/varnish/vmods/ | grep memcached libvmod_memcached.a libvmod_memcached.la libvmod_memcached.so
The last missing thing is the default.vcl file.
import std;
import memcached;
backend default {
.host = "127.0.0.1";
.port = "80";
}
sub vcl_init {
memcached.servers({"--SERVER=localhost:11211 --NAMESPACE="memc.sess.key.""});
return (ok);
}
sub vcl_recv {
if (req.restarts == 0) {
if (req.http.x-forwarded-for) {
set req.http.X-Forwarded-For =
req.http.X-Forwarded-For + ", " + client.ip;
} else {
set req.http.X-Forwarded-For = client.ip;
}
}
if (req.request != "GET" &&
req.request != "HEAD" &&
req.request != "PUT" &&
req.request != "POST" &&
req.request != "TRACE" &&
req.request != "OPTIONS" &&
req.request != "DELETE") {
/* Non-RFC2616 or CONNECT which is weird. */
return (pipe);
}
if (req.request != "GET" && req.request != "HEAD") {
/* We only deal with GET and HEAD by default */
return (pass);
}
set req.http._sess = regsub( regsub( req.http.Cookie, ".*PHPSESSID=", "" ), ";.*", "" );
std.log( "Cookie: " + req.http._sess );
set req.http._sess = memcached.get( req.http._sess );
std.log( "Session: " + req.http._sess );
return (lookup);
}
sub vcl_pipe {
return (pipe);
}
sub vcl_pass {
return (pass);
}
sub vcl_hash {
hash_data(req.url);
if (req.http.host) {
hash_data(req.http.host);
} else {
hash_data(server.ip);
}
if( req.http._sess && req.http._sess ~ "lang" ) {
set req.http._lang = regsub( regsub( req.http._sess, ".*lang.*?x22", "" ), "x22.*", "" );
std.log( "Lang: " + req.http._lang );
hash_data( req.http._lang );
}
return (hash);
}
sub vcl_hit {
return (deliver);
}
sub vcl_miss {
return (fetch);
}
sub vcl_fetch {
if( req.url ~ "^/$" ) {
set beresp.ttl = 30m;
remove beresp.http.set-cookie;
return(deliver);
}
if (beresp.ttl <= 0s ||
beresp.http.Set-Cookie ||
beresp.http.Vary == "*") {
/*
* Mark as "Hit-For-Pass" for the next 2 minutes
*/
set beresp.ttl = 520 s;
return (hit_for_pass);
}
return (deliver);
}
sub vcl_deliver {
return (deliver);
}
sub vcl_error {
set obj.http.Content-Type = "text/html; charset=utf-8";
set obj.http.Retry-After = "5";
synthetic {"
ERROR
"};
return (deliver);
}
sub vcl_fini {
return (ok);
}
There are few interesting things going on here.
sub vcl_init {
memcached.servers({"--SERVER=localhost:11211 --NAMESPACE="memc.sess.key.""});
return (ok);
}
As you probably can guess Varnish will connect to the memcached server on init.
Now look at the bottom of the vcl_recv function.
set req.http._sess = regsub( regsub( req.http.Cookie, ".*PHPSESSID=", "" ), ";.*", "" ); std.log( "Cookie: " + req.http._sess ); set req.http._sess = memcached.get( req.http._sess ); std.log( "Session: " + req.http._sess );
VCL language doesn’t allow to define new variables although you can reuse the predefined one (like in this example “req.http“). By the end of this block you should have the whole PHP session stored inside req.http._sess.
You can use
$ varnishlog | grep Log
to see output of the std.log function.
The most important code happens inside the vcl_hash subroutine.
if( req.http._sess && req.http._sess ~ "lang" ) {
set req.http._lang = regsub( regsub( req.http._sess, ".*lang.*?x22", "" ), "x22.*", "" );
std.log( "Lang: " + req.http._lang );
hash_data( req.http._lang );
}
You can read more about VCL subroutines here but in a nutshell vcl_hash is responsible for building a hash string under which a cache is going to be saved.
By default Varnish is caching per URL and host but we have to extend it by a language name. This is exactly what happens here. A full hash string will look more less like this:
"/" + "localhost:8080" + "English"
The last thing worth explaining is what happens inside the vcl_fetch.
sub vcl_fetch {
if( req.url ~ "^/$" ) {
set beresp.ttl = 30m;
remove beresp.http.set-cookie;
return(deliver);
}
If there is a cookie attached to a request Varnish will never return cached content. It comes from an assumption that if there is a cookie the page must be dynamic.
The point of this exercise if to handle dynamic content so we walk around this limitation for http://localhost:8080/ requests by unsetting cookies (it happens only in the Varnish scope).
Now you can start Varnish server (don’t forget to type start).
$ sudo varnishd -f /usr/local/etc/varnish/default.vcl -s malloc,128M -T 127.0.0.1:2000 -a 0.0.0.0:8080 -d Platform: Linux,3.5.0-30-generic,x86_64,-smalloc,-smalloc,-hcritbit 200 244 ----------------------------- Varnish Cache CLI 1.0 ----------------------------- Linux,3.5.0-30-generic,x86_64,-smalloc,-smalloc,-hcritbit Type 'help' for command list. Type 'quit' to close CLI session. Type 'start' to launch worker process. start child (4913) Started 200 0 Child (4913) said Child starts
Open two different web browsers, go to http://localhost:8080/ and start changing languages. POST requests are always forwarded to the web server so session value should be updated. For every GET Varnish should return an appropriate content (according to the current language selection) from cache.
It’s little bit tricky to set it up for the first time but the reward is worth it. Making the Varnish Cache aware of user’s status gives much more flexibility and allows to handle more requests directly from cache. That dramatically drops your hosting costs and increases capacity of your server. Give it a go.

It’s not my first post about Varnish Cache (Boost WordPress performance) but this time I’m going to show a generic example which can work with any type of PHP application.
You can install Varnish Cache via good old “apt-get” although I prefer to compile it from sources. The reason for that is I usually use it with memcached module which requires Varnish Cache source code.
Varnish requires libpcre.
$ sudo apt-get install libpcre3-dev
Install the software.
$ wget http://repo.varnish-cache.org/source/varnish-3.0.3.tar.gz $ tar zxfv varnish-3.0.3.tar.gz $ ./configure $ make $ sudo make install
If you didn’t use any –prefix= the software should be installed under /usr/local.
$ whereis varnishd varnishd: /usr/local/sbin/varnishd
Config file should be in /usr/local/etc/varnish/default.vcl but it’s not that important.
Now it’s a time to create a very simple PHP script and save it as index.php.
Hello World
Cache from:
ESI is not working!
You might be wondering what is the ESI tag. It stands for Edge Side Includes and it’s a very cool feature.
A web page usually consists of multiple blocks. Some of them like layout change almost never while other might be fully dynamic. Varnish Cache allows to break down a page into such a blocks and cache them with a different expire time. Depends on your needs you can setup Varnish to pull those blocks from different web servers (for example you can have a dedicated host for a real time data).
Going back to our example Varnish will replace “” with a content from “/time.php“. Everything inside the
tag will be removed from the page.
Lets create the time.php script.
Cache from:
It couldn’t be simpler.
Right now you should have 2 pages:
http://127.0.0.1/
http://127.0.0.1/time.php
Now it’s the time to create the varnish configuration file.
$ vim /usr/local/etc/varnish/default.vcl
backend default {
.host = "127.0.0.1";
.port = "80";
}
sub vcl_recv {
if (req.restarts == 0) {
if (req.http.x-forwarded-for) {
set req.http.X-Forwarded-For =
req.http.X-Forwarded-For + ", " + client.ip;
} else {
set req.http.X-Forwarded-For = client.ip;
}
}
if (req.request != "GET" &&
req.request != "HEAD" &&
req.request != "PUT" &&
req.request != "POST" &&
req.request != "TRACE" &&
req.request != "OPTIONS" &&
req.request != "DELETE") {
return (pipe);
}
if (req.request != "GET" && req.request != "HEAD") {
return (pass);
}
if (req.http.Authorization || req.http.Cookie) {
return (pass);
}
return (lookup);
}
sub vcl_pipe {
return (pipe);
}
sub vcl_pass {
return (pass);
}
sub vcl_hash {
hash_data(req.url);
if (req.http.host) {
hash_data(req.http.host);
} else {
hash_data(server.ip);
}
return (hash);
}
sub vcl_hit {
return (deliver);
}
sub vcl_miss {
return (fetch);
}
sub vcl_fetch {
if( req.url == "/") {
set beresp.do_esi = true; /* Do ESI processing */
set beresp.ttl = 120s; /* Sets the TTL on the HTML above */
} elseif (req.url == "/time.php") {
set beresp.ttl = 5s; /* Sets a one minute TTL on */
}
if (beresp.ttl <= 0s ||
beresp.http.Set-Cookie ||
beresp.http.Vary == "*") {
set beresp.ttl = 120 s;
return (hit_for_pass);
}
return (deliver);
}
sub vcl_deliver {
return (deliver);
}
sub vcl_error {
set obj.http.Content-Type = "text/html; charset=utf-8";
set obj.http.Retry-After = "5";
synthetic {"
"} + obj.status + " " + obj.response + {"
Error "} + obj.status + " " + obj.response + {"
"} + obj.response + {"
Guru Meditation:
XID: "} + req.xid + {"
Varnish cache server
"};
return (deliver);
}
sub vcl_init {
return (ok);
}
sub vcl_fini {
return (ok);
}
If you are new to Varnish Cache this might look little bit overwhelming but I assure you there is no magic here. This is the default configuration which is well explained in the manual. What’s interesting from our example’s point of view is inside vcl_fetch.
sub vcl_fetch {
if( req.url == "/") {
set beresp.do_esi = true; /* Do ESI processing */
set beresp.ttl = 120s; /* Sets the TTL on the HTML above */
} elseif (req.url == "/time.php") {
set beresp.ttl = 5s; /* Sets a one minute TTL on */
}
For the “/” request we turn the ESI processing on and we cache content from this location for 120 seconds. Content returned from “/time.php” will be stored only for 5 seconds.
Lets run varnish and give it a go.
sudo varnishd -f /usr/local/etc/varnish/default.vcl -s malloc,128M -T 127.0.0.1:2000 -a 0.0.0.0:8080 -d Platform: Linux,3.5.0-30-generic,x86_64,-smalloc,-smalloc,-hcritbit 200 244 ----------------------------- Varnish Cache CLI 1.0 ----------------------------- Linux,3.5.0-30-generic,x86_64,-smalloc,-smalloc,-hcritbit Type 'help' for command list. Type 'quit' to close CLI session. Type 'start' to launch worker process.
One thing to notice is “-d” flag at the end of the above line. That will run Varnish Cache in debug mode so you have to type “start” to run it.
start child (5101) Started 200 0 Child (5101) said Child starts
No open new tab in your web browser and visit http://127.0.0.1:8080/.
You should see something like that:
Hello World
Cache from: Sat, 06 Jul 13 22:20:47 +0100
Cache from: Sat, 06 Jul 13 22:20:47 +0100
Interesting thing happen when you refresh the page. First two line should stay the same for 2 minutes while the last one should change every 5 seconds. Isn’t that great?
This is not everything. There are cases when you have to invalidate cache without waiting for it to expire.
Varnish 3.x allows to ban cached data https://www.varnish-cache.org/docs/3.0/tutorial/purging.html. Modify the default.vcl file.
sub vcl_recv {
if( req.url ~ "^/clearcache" ) {
# for example /clearcache?uri=foo/bar
if( req.url ~ "uri=" ) {
ban( "req.url ~ ^/" + regsub( req.url, ".*uri=", "") );
}
error 200 "Ban added";
}
Obviously in the production environment you need additional condition to allow calling “/clearcache” only from certain IP addresses.
Stop Varnish server (ctrl + c) and start it again (don’t forget to type “start”).
$ sudo varnishd -f /usr/local/etc/varnish/default.vcl -s malloc,128M -T 127.0.0.1:2000 -a 0.0.0.0:8080 -d
Now if you go to http://127.0.0.1:8080/clearcache?uri= cache for “/” will be invalidated. You can see all active bans in you server console by typing ban.list.
ban.list 200 52 Present bans: 1373146379.588119 1 req.url ~ ^/
Varnish will add bans only if there is a cached content (for that rule).
The last thing is to call the clearcache URL from PHP. After all we don’t want to manually refresh that page.
Lets create another script and call it clearcache.php.
$val ) {
curl_setopt( $ch, $opt, $val );
}
if( ! empty( $post ) ) {
curl_setopt( $ch, CURLOPT_POST, 1 );
curl_setopt( $ch, CURLOPT_POSTFIELDS, http_build_query( $post ) );
}
$output = curl_exec( $ch );
if( $output === false ) {
throw new Exception( curl_error( $ch ) );
}
$info = curl_getinfo($ch);
curl_close( $ch );
return $output;
}
}
$ret = CURL::getUrl( 'http://127.0.0.1:8080/clearcache?uri=' );
if( preg_match( '/200 Ban added/', $ret ) ) {
echo 'cache cleared';
} else {
echo 'error
';
echo $ret;
}
Now you can visit http://127.0.0.1/clearcache.php to give it a go.
If you need to troubleshoot your VCL script put
import std;
in the first line and echo data with
std.log( );
Debug data will be pushed to the Varnish Cache log and to read it run:
$ varnishlog | grep Log
Thank you for getting to the end of this post. Varnish Cache is a great peace of software and it’s worth knowing it. It’s little bit techie and programming VCL script could be easier but it will make your application fly.

Lets create an alternative way to define a class. The simplest class definition allowed in PHP looks like this:
<?php
class ClassName {}
We can simplify the syntax and replace the curly brackets with semicolon.
<?php class ClassName;
If you try to execute this code it will obviously throw an error. That’s not a problem, we can fix it.
First step is to install some software.
$ sudo apt-get install bison re2c
PHP is written in C however the parser is created with Bison. Bison is a parser generator. The home page defines it as: a general-purpose parser generator that converts an annotated context-free grammar into a deterministic LR or generalized LR (GLR) parser employing LALR parser tables.
It’s a very powerful peace of software and one can write a whole book about it. If you would like to learn more I refer you to the documentation. It’s not a very easy read but there is a good example. If you will ever want to create a programming language that might be the good place to start.
Go to the http://php.net and get the latest PHP sources.
$ tar xvjf php-5.4.14.tar.bz2 $ cd php-5.4.14 $ ./configure $ cd Zend $ ls
Take your hat off. You are looking at the core of PHP. Code in those files powers vast majority of web servers. Lets break it.
A default extension for Bison files is “y”.
$ ls *.y zend_ini_parser.y zend_language_parser.y
We don’t want to mess with the “ini” syntax so the only choice is “zend_language_parser.y“. Open it with your editor of choice.
If you search for “class” you will find
%token T_CLASS "class (T_CLASS)"
Parsers like to operate on tokens. The “class” token is “T_CLASS“. If you search for the “T_CLASS” you will find something like that:
class_entry_type:
T_CLASS { $$.u.op.opline_num = CG(zend_lineno); $$.EA = 0; }
| T_ABSTRACT T_CLASS { $$.u.op.opline_num = CG(zend_lineno); $$.EA = ZEND_ACC_EXPLICIT_ABSTRACT_CLASS; }
| T_TRAIT { $$.u.op.opline_num = CG(zend_lineno); $$.EA = ZEND_ACC_TRAIT; }
| T_FINAL T_CLASS { $$.u.op.opline_num = CG(zend_lineno); $$.EA = ZEND_ACC_FINAL_CLASS; }
;
You are looking at four different ways to define a class.
- class
- abstract class
- trait
- final class
In curly brackets you can see some low level assignments. I can only guess what are they for. Lets ignore them😉
We are on a right track but it’s not exactly what we’re looking for. Search for “class_entry_type” which groups those four definitions.
That takes you to the final destination. It’s easy but not very readable at the beginning.
unticked_class_declaration_statement:
class_entry_type T_STRING extends_from
{ zend_do_begin_class_declaration(&$1, &$2, &$3 TSRMLS_CC); }
implements_list
'{'
class_statement_list
'}' { zend_do_end_class_declaration(&$1, &$3 TSRMLS_CC); }
| interface_entry T_STRING
{ zend_do_begin_class_declaration(&$1, &$2, NULL TSRMLS_CC); }
interface_extends_list
'{'
class_statement_list
'}' { zend_do_end_class_declaration(&$1, NULL TSRMLS_CC); }
;
There are two declarations here. One for a class and one for an interface. We are interested in the first one. It starts with “class_entry_type” which resolves to: class | abstract class | trait | final class. Next element is a token T_STRING. That’s going to be the class name. Another element “extends_from” is a group. It can be “extends T_STRING” or nothing.
After that parser calls the Zend engine to begin class declaration.
{ zend_do_begin_class_declaration(&$1, &$2, &$3 TSRMLS_CC); }
You can find this function in zend_compiler.c file.
void zend_do_begin_class_declaration(const znode *class_token, znode *class_name, const znode *parent_class_name TSRMLS_DC)
First argument is a class token “class_entry_type“, second is a class name “T_STRING” and the last one is a parent class “extends_from“.
Under that we have another group “implements_list”. I’m sure you can guess it. Yes, it’s for assigning interfaces. Following lines define the mandatory class body: opening bracket “{“, “class_statement_list” group and the closing bracket “}“. Finally the parser informs Zend engine that the class declaration has ended.
{ zend_do_end_class_declaration(&$1, &$3 TSRMLS_CC); }
We need to duplicate that code but without class body definition.
unticked_class_declaration_statement:
class_entry_type T_STRING extends_from
{ zend_do_begin_class_declaration(&$1, &$2, &$3 TSRMLS_CC); }
';' { zend_do_end_class_declaration(&$1, &$3 TSRMLS_CC);
| class_entry_type T_STRING extends_from
{ zend_do_begin_class_declaration(&$1, &$2, &$3 TSRMLS_CC); }
implements_list
'{'
class_statement_list
'}' { zend_do_end_class_declaration(&$1, &$3 TSRMLS_CC); }
| interface_entry T_STRING
{ zend_do_begin_class_declaration(&$1, &$2, NULL TSRMLS_CC); }
interface_extends_list
'{'
class_statement_list
'}' { zend_do_end_class_declaration(&$1, NULL TSRMLS_CC); }
;
It was quite simple, wasn’t it? Now you just have to compile it.
$ cd .. $ make
First compilation is always taking a while.
$ vim test.php
Paste the test code.
bar = 10; print_r( $a );
Go and test your hack.
$ sapi/cli/php test.php Bar Object ( [bar] => 10 )
Well done, you’ve hacked PHP!
Lets add one more thing. In PHP you define a class with the “class” keyword. How about make it shorter? “cls” should do fine.
Look for Lexer files.
$ cd Zend/ $ ls *.l zend_ini_scanner.l zend_language_scanner.l
Bison file was operating on tokens. Lexer allow you to define how to convert a code into the tokens.
Opens zend_language_scanner.l and search for “class“.
"class" {
return T_CLASS;
}
Duplicate this block and change class to cls.
"cls" {
return T_CLASS;
}
"class" {
return T_CLASS;
}
Job done. Compile the code and you can use “cls” instead of the “class” word.
Wasn’t that fun? I hope you enjoyed it as much as I did. Play around, break it. If you really like it think about closing some bugs on https://bugs.php.net/.

In order to integrate your program with Google Drive you need to create a Google API project. You can do it at Google console page.

Press “Create Project” button and select services you want to use with the project. For the purpose of this example “Drive API” is enough.

Once the service is enabled click on API Access from the left hand side navigation.

Click on “Create an OAuth 2.0 client ID” button. Make up a project name and click “next”. On the Client ID settings page choose “Service Account” as the application type.

Press “Create client ID” button. Click “Download private key” to download… you guess it – private key! You need it to access your account. Bear in mind you can download it only once.

Now your service account it created. You will need the client id and email address in a second. Leave the Google console page open.

There is one important thing you need to be aware of. Service account is not your Google account. If you upload files to the service account’s drive you won’t see them in your Google Drive. It’s not a big problem because the uploaded files can be shared.
If for some reason you need to have files uploaded directly to your account you can’t use the service account. You will have to create a web application instead. That change the way how you authenticate. Web application requires a manual journey though OAuth. Backups usually work in background and there is no web interface for OAuth redirections. For that reason I prefer to use a private key.
Now when your API project is created you can download an example script I prepared for this post. It’s a command line utility in PHP which uploads a file to shared folder on Google Drive. It’s available on my GitHub account: cp2goole. For your convenience the script comes with Google API but don’t use it with your projects. Download the latest API with examples from the official page https://developers.google.com/drive/quickstart-php.
$ git clone https://github.com/lukaszkujawa/cp2google.git $ cd cp2google/ $ vim cp2google.php
You will have to modify first lines of the script.
<?php define( 'BACKUP_FOLDER', 'PHPBackups' ); define( 'SHARE_WITH_GOOGLE_EMAIL', '[email protected]' ); define( 'CLIENT_ID', '700692987478.apps.googleusercontent.com' ); define( 'SERVICE_ACCOUNT_NAME', '[email protected]' ); define( 'KEY_PATH', '../866a0f5841d09660ac6d4ac50ced1847b921f811-privatekey.p12');
BACKUP_FOLDER – name of shared folder. The script will create it at the first run.
SHARE_WITH_GOOGLE_EMAIL – your google account.
CLIENT_ID – your project’s client id
SERVICE_ACCOUNT_NAME – your project’s account name. It’s called e-mail address on the console page.
KEY_PATH – path to the downloaded private key.
Replace those values to match your configuration. Save changes are run the file.
$ php cp2google.php README.md Uploading README.md to Google Drive Creating folder... File: 0B9_ZqV369SiSM19KbTROWldqcFk created
Now check your Google Drive. You should find a new folder in the “Shared with me” section. You also should receive an e-mail saying that the file has been shared with you.
I won’t get though the code because it’s quite simple to understand. The only thing worth mentioning is that on Google Drive files and folders are the same thing. Folder has a specific mime type which is “application/vnd.google-apps.folder”.
Full documentation of Google Drive API can be found here https://developers.google.com/drive/v2/reference/. Most of the calls have an example in: JAVA, .NET, PHP, Python, Ruby, JavaScript, Go and Objective-C. It should be enough for most people😉
Google was always very generous when it comes down to storage. There are multiple ways to take advantage of that and backups are one of them. I wouldn’t use it to store business critical data but everything else should be just fine. It feels much more convenient then anything else.

All of that is very exciting and I’m highly impressed how the service is designed but… it’s relatively new product. If you play with the tutorial (which by the way is great) running multiple services on the same host does’t cause problems. Setting the service for production environment and using it is a different story. There are still some unresolved issues which can confuse for hours if not days.
I would like to share my experience with setting up Solr Cloud and highlight problems I came across. If you are completely new to the subject I recommend you to read Solr Cloud tutorial first. If you new to Solr have a look into my previous post.
All applications we are going to use in this post are written in Java. I’m doing my best to setup the service up to the highest standards but I’m not a Java developer. There might be some things which could be done better. If that’s the case I would love to hear your feedback.
Goals and assumptions for this tutorial are:
- Solr 4.2.1 – this’s the latest version of Solr at the time of writing this post.
- Tomcat7 – Solr comes with Jetty which is very helpful for development although our goal is production setup. The service will have to be monitor and maintained by sysops. They are usually more familiar with TomCat7 than other solutions.
- External ZooKeeper – Solr has ZooKeeper build in but it’s not recommended to use it in production.
- Operating system Ubuntu 12.04 – personal preferences (sorry RedHat folks).
If you would like to try this setup but you don’t have an access to multiple servers there are two options:
- Use amazon EC2 micro instances (it’s free).
- Use virtualisation – I recommend VMWare player. It’s free and fast.
A journey of a thousand miles begins with a single step. Lets log in to the first server and download ZooKeeper, Solr and TomCat7.
$ sudo apt-get install tomcat7 tomcat7-admin $ wget http://apache.mirrors.timporter.net/zookeeper/current/zookeeper-3.4.5.tar.gz $ wget http://mirrors.ukfast.co.uk/sites/ftp.apache.org/lucene/solr/4.2.1/solr-4.2.1.tgz
My links might be out of date. Make sure you download the latest version of ZooKeeper and Solr.
Before we do any configuration lets check your host name.
$ hostname ubuntu
Now look for it in /etc/hosts
$ sudo vim /etc/hosts
If you find something like this:
127.0.1.1 ubuntu
Change the IP to your LAN IP address. This tiny thing gave me guru meditation for few days. It will make at least one of your Solr nodes to register as “127.0.1.1”. Localhost address doesn’t make any sense from cloud’s point of view. That will populate multiple issues with replication and leader election. It’s later hard to guess that all of those problems come from this silly source. Don’t repeat my mistake.
Unpack downloaded software.
$ tar zxfv zookeeper-3.4.5.tgz $ tar zxfv solr-4.2.1.tgz
The easier job is to setup ZooKeeper. You will do it only once on the first server. ZooKeeper scales well and you can run it on all Solr nodes if required. There is no need for this at the moment so we can take single server approach.
Create a directory for zookeeper data and set configuration to point to that place.
$ sudo mkdir -p /var/lib/zookeeper $ cd zookeeper-3.4.5/ $ cp conf/zoo_sample.cfg conf/zoo.cfg $ vim conf/zoo.cfg
Find dataDir and paste appropriate path.
dataDir=/var/lib/zookeeper
Start ZooKeeper.
$ bin/zkServer.sh start JMX enabled by default Using config: /home/lukasz/zookeeper-3.4.5/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
If you like you can use ZooKeeper client to connect with the server.
$ bin/zkCli.sh -server 127.0.0.1:2181 [zk: 127.0.0.1:2181(CONNECTED) 0] ls / [zookeeper]
Type “quit” to exit.
Now lets insert Solr configuration into ZooKeeper. Go to Solr directory and have a look into solr-webapp. It should be empty.
$ cd solr-4.2.1/example/ $ ls solr-webapp/
Please notice I’m using the example directory. In real live you obviously want to rename it to something better. The same with collections. I’m going to use the default collection1 for this tutorial.
If your solr-webapp doesn’t have solr.war inside run Solr for few seconds to make it extract the file.
# java -jar start.jar 2013-04-05 09:38:58.132:INFO:oejs.Server:jetty-8.1.8.v20121106 2013-04-05 09:38:58.150:INFO:oejdp.ScanningAppProvider:Deployment monitor /root/solr-4.2.1/example/contexts at interval 0 2013-04-05 09:38:58.153:INFO:oejd.DeploymentManager:Deployable added: /root/solr-4.2.1/example/contexts/solr-jetty-context.xml 2013-04-05 09:38:58.209:INFO:oejw.WebInfConfiguration:Extract jar:file:/root/solr-4.2.1/example/webapps/solr.war!/ to /root/solr-4.2.1/example/solr-webapp/webapp
After this line you can press ctrl+c to stop the server.
$ ls webapps/solr.war webapps/solr.war
Now we can start uploading configuration to the ZooKeeper.
$ cloud-scripts/zkcli.sh -cmd upconfig -zkhost 127.0.0.1:2181 -d solr/collection1/conf/ -n default1 $ cloud-scripts/zkcli.sh -cmd linkconfig -zkhost 127.0.0.1:2181 -collection collection1 -confname default1 -solrhome solr $ cloud-scripts/zkcli.sh -cmd bootstrap -zkhost 127.0.0.1:2181 -solrhome solr
If you would like to learn more about the zkcli script have a look here http://docs.lucidworks.com/display/solr/Command+Line+Utilities.
Now if you login to ZooKeeper and run “ls /” command you should see the uploaded data.
$ bin/zkCli.sh -server 127.0.0.1:2181 [zk: localhost:2181(CONNECTED) 0] ls / [configs, zookeeper, clusterstate.json, aliases.json, live_nodes, overseer, collections, overseer_elect] [zk: 127.0.0.1:2181(CONNECTED) 1] ls /configs [default1] [zk: 127.0.0.1:2181(CONNECTED) 3] ls /configs/default1 [admin-extra.menu-top.html, currency.xml, protwords.txt, mapping-FoldToASCII.txt, solrconfig.xml, lang, stopwords.txt, spellings.txt, mapping-ISOLatin1Accent.txt, admin-extra.html, xslt, scripts.conf, synonyms.txt, update-script.js, velocity, elevate.xml, admin-extra.menu-bottom.html, schema.xml] [zk: localhost:2181(CONNECTED) 4] get /configs/default1/schema.xml // content of your schema.xml [zk: 127.0.0.1:2181(CONNECTED) 5] quit Quitting…
This step is obviously not required but it’s good to know what happens inside each service and how to get there.
If you impatient then you can go to “solr-4.2.1/example/” and run the service.
$ java -DzkHost=localhost:2181 -jar start.jar
it should work in Cloud mode and if you are happy with running it that way you can skip TomCat setup. If that’s the case visit http://SERVER01_IP:8080/solr/#/~cloud to confirm it’s working.
If you go to that URL have a look into first sub item in the navigation. It’s called “Tree”. Does it look familiar? Yes, it’s ZooKeeper’s data.
The final step is to setup TomCat. Stop Solr (Ctrl + c) if you run it and go to TomCat’s directory.
$ cd /etc/tomcat7/Catalina/localhost/ $ vim solr.xml
Paste below configuration. Make sure docBase and Environment path match your setup.
Enable admin user for TomCat.
$ vim /etc/tomcat7/tomcat-users.xml
Add
to tomcat-users tag.
You are almost there. The last thing is to “tell” Solr to use ZooKeeper. We already know how to do it from command line. When you run Solr from an external container you have to edit solr.xml.
$ vim solr-4.2.1/example/solr/solr.xml
Find top tag called solr and add zkHost attribute.
While you are editing solr.xml go to cores tag and set hostPort attribute to 8080.
Restart Tomcat.
$ sudo /etc/init.d/tomcat7 restart
Open web browser and go to http://SERVER01_IP:8080/manager/html. You will be asked for username and password which you set in the previous step (admin/secret).
Find “/solr” in Applications list and click on “start” in commands column. If it fails with a message “FAIL – Application at context path /solr could not be started” it’s most likely permissions issue. You can resolve it with
$ chown tomcat7.tomcat7 -R /home/lukasz/solr-4.2.1/
If it still doesn’t work you can troubleshoot it in “/var/log/tomcat7/catalina.*.log”.
Once the service is running you can access it under http://SERVER01_IP:8080/solr/#/.
That was first server. To have a cloud you need at least one more. The steps are exactly the same with a difference you can skip everything related to ZooKeeper. Make sure to set correct IP address for zkHost in solr.xml.
Run second server and go to http://SERVER01_IP:8080/solr/#/~cloud. You should see two servers replicating Collection1.

Just to remind you. If one of your servers has local IP like 127.0.1.1 there is a problem with your /etc/hosts file. If you made any mistake you can always start again. Stop TomCat servers, login to ZooKeeper and remove “clusterstate.json”.
[zk: localhost:2181(CONNECTED) 1] rmr /clusterstate.json
Now you can insert some data into your index.
$ cd solr-4.2.1/example/exampledocs/ $ vim post.sh
Bash script needs to be updated because it points to the default port.
URL=http://localhost:8080/solr/update
Run the script.
$ ./post.sh mem.xml Posting file mem.xml to http://localhost:8080/solr/update 075 064
So far so good. Now lets use Collections API to create a new collection.
http://ONE_OF_YOUR_SERVERS:8080/solr/admin/collections?action=CREATE&name=hello
&numShards=2&replicationFactor=1&collection.configName=default1
This should add new collection called “hello”. The collection will use previously uploaded configuration “default1” and is going to be split into both server.

That looks more interesting. If you click on core selector (bottom of the left hand side navigation) you will notice the core is called “hello_shard1_replica1”. On the other server the name will be “hello_shard2_replica1”. You can still use “hello” name to query any of the server, for example:
http://ONE_OF_YOUR_SERVERS:8080/solr/hello/select?q=*%3A*&wt=xml&indent=true
If you are not on Solr 4.3 yet you have to be aware of very confusing bug – SOLR-4584. On some occasions you might not wish to store particular index on every server. For example, your cloud consists of 3 servers and you set shards to 1 and replication factor to 2. If you make a query to a server which physically don’t store the data you will get an error. This is obviously undesired behavior and will get fix. Right now you have to live with it so my recommendation is to use all servers.
It takes some effort to set everything up but it’s definitely worth it. There are some problems around Solr and the Cloud setup could be easier but I’m convinced all of those issues will be eventually addressed. If you still have some capacity for more Solr knowledge watch this speech: Solr 4: The SolrCloud Architecture.

If you’ve ever been trying to squeeze more out of hardware you must have come across Nginx (engine x). Nginx usually appears in context of PHP-FPM (FastCGI Process Manager) and APC (Alternative PHP Cache). This setup is often pitched to be the ultimate combo for a web server but what that really means? How much faster a PHP application is going to be on a different web server? I had to check it and the answer as often is – that depends.
I benchmarked three different types of PHP software:
– Large application based on Zend Framework 1
– Small PHP script
– WordPress
The software was hosted on Amazon EC2 large instance. All benchmarks were run from EC2 Tiny instance to be as close as it possible to the web server.
To make sure I benchmark web servers instead of disk I/O I set all logs to go to memory (/dev/shm). PHP sessions were directed to memcached.
Both servers were using Zend Optimizer Plus with opcache.revalidate_freq set to 1 hour. I use Zend Optimizer because APC wasn’t stable for me with PHP 5.4.x.
If you aren’t familiar with PHP accelerators they convert PHP scripts into byte code and keep them in shared memory. That brings significant boost of performance (40-90%) because PHP scripts don’t have to be read from a disc and parsed on every request. Using the accelerator helped me removing I/O from the equation.
It’s very important to make sure Apache won’t read .htaccess. You can achieve it by setting Allow Overwrite to none. Parsing htaccess in real time will drop performance on the Apache side. It’s recommended to not use this file in production environment.
I kept dstats open during all test to make sure there is no IO and CPU cycles lost (after all EC2 is only a virtual server).
First set of benchmarks was performed against the large ZF application. Each test consisted of 1000 requests and different level of concurrency (30/60/100). I tested 3 different setups: Apache2 with PHP5_MOD, Apache2 with PHP-FPM and NGINX with PHP-FRM.

Nginx is slightly ahead of Apache2 with FastCGI. The difference is usually 3.5%. The other interesting observation is that PHP-FPM performs only slightly better then PHP5_MOD.
The second test was against a tiny PHP script. The script was printing “Lorem Ipsum” 50 times. I benchmarked it with 1000 requests and concurrency set to 50.

As previously there is a slight difference (4%) between web servers.
The last set of tests was done against WordPress. First I benchmarked the installation page. It was worth doing because it’s almost a static page without much computing or DB interaction.

This is very interesting, 32.5% difference in performance. Nginx had a chance to unfold wings because it loves static content.
The last check was against WordPress homepage. There were 2 post and no caching.

There isn’t big difference between Apache2 and Nginx in PHP context. Yes, Nginx can be much faster when delivering static content but it won’t speed up PHP execution. Running a PHP script seams to be so CPU challenging task that it completely eclipse any gain from a web server.
Obviously a web application doesn’t consist of PHP files only. There are plenty of static assets which have to be delivered. If you are not planning to use any content distribution network Nginx will definitely help with that.
The conclusion is that it doesn’t matter which server you are going to chose. The real performance wins are purely on the PHP side. Using an accelerator with caching can multiply the number of requests your infrastructure can maintain.
I guess the next big thing will be compiling PHP into binary and running it as FastCGI. Unfortunately it might take some time to have a stable all purpose HipHop-PHP. If you need more performance now, look into Varnish Cache.
I’m going to use Nginx because I’m not tied to a particular web server. It’s slightly faster for PHP (and apparently takes less memory but I’m not able to prove it) and much faster for static resources. Why not to use it?
You might like to read


First you have to create an account. Go to http://aws.amazon.com/ and register. Once you have an account, login and go to “AWS Managment Console”. The link is available under “My Account / Console” tab.
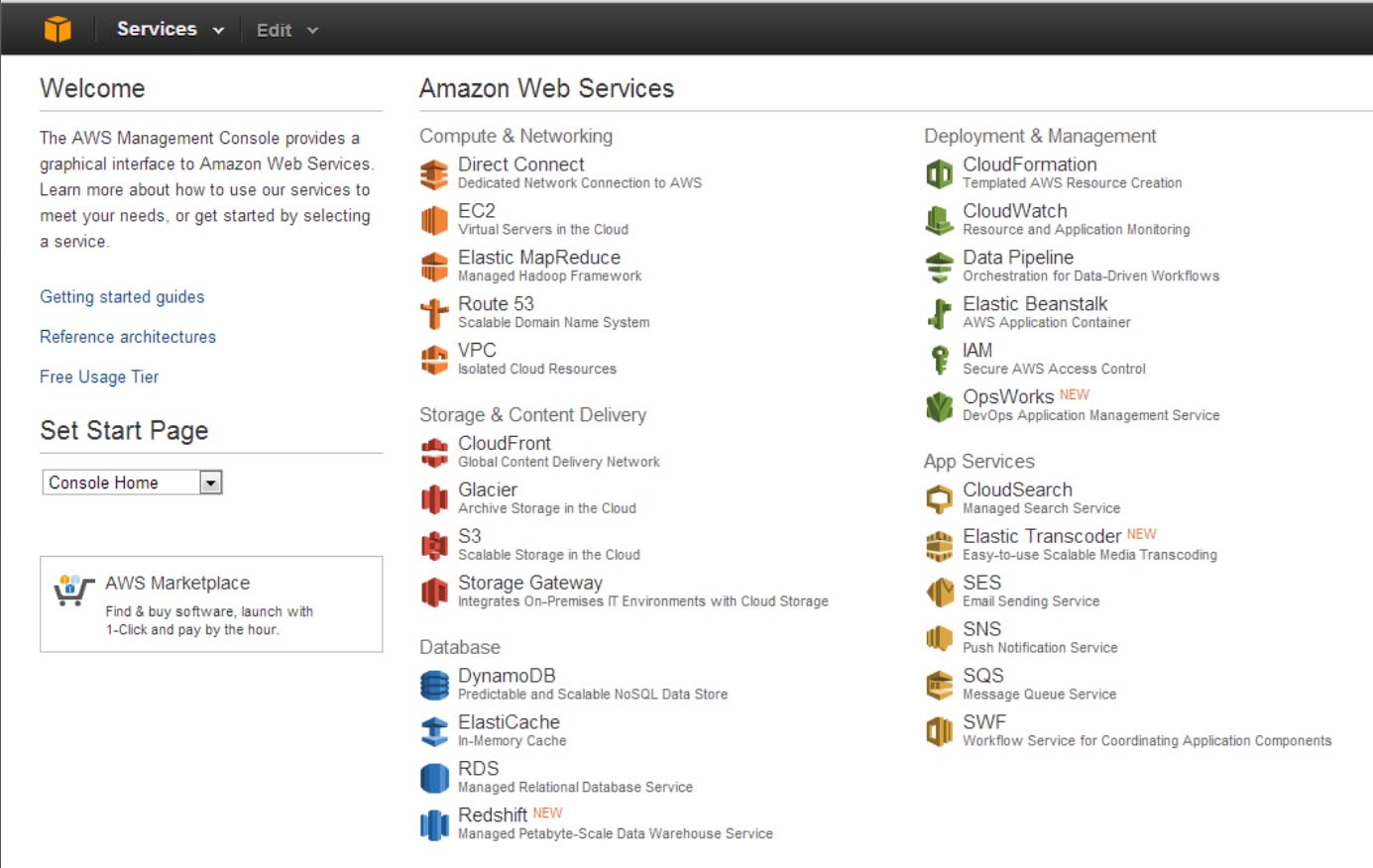
Whooa… that’s lots of products. Don’t worry, it’s not that complicated as it looks.
To install your software on Amazon you need a server. Choose EC2 from Compute & Networking section. In the realm of cloud computing servers are called instances. Click on “instance” from left hand side navigation. You should see something like on the below image (obviously your instances list should be empty).

To create a new instance click on a big button called “Launch Instance”. That should bring a JavaScript modal.

Stay with the “Classic Wizzard” and click continue.

Now it’s getting interesting. On this screen you are asked to select your distribution. My choice is 64bit Ubuntu but it’s just a personal preference. Before we go any further have a quick look on “My AMIs” tab. After you launch and setup your instance you can create an image from it. Later when you will require more computing power you can fire new instances from the image. Very cool, isn’t it? Select your distribution and go to the next step.

Now you have to select instance type. Go for the first option called T1 Micro. Make sure it says “Free tier eligible”. Click continue.
The next step is called “Advance Instance Option”. There is nothing you want to change there. Click continue. The same on “Storage Device Configuration” and on another page.

At this step you have to create a key pair. You will need it to login into your EC2 instance. If you are new to SSH keys you can find more details here. Always protect and backup keys. You can’t download them from Amazon and you can’t regenerate them for running instance. If you lose it you won’t be able to login. I learned it the hard way.
The next step is to select security group. It allows you to open / close certain ports on your server. You can go for the default option and edit the group later.
That’s it. The last screen is summary of your settings. If you are happy with everything click on “Launch” button.

To find out what is the address of your instance select it from the list. It should be something like “ec2-54-246-44-13.eu-west-1.compute.amazonaws.com”. If you are on Linux or Mac you can login immediately.
$ ssh -i path/to/key.pem ubuntu@you-address
Windows users need to convert the .pem key to format compatible with putty. Dowload PuTTYgen.exe, open it and select “Convertions > Import key”. Chose your Amazon key. Once the file is loaded select “File > Save private key”. Password protection is optional, you don’t have to do it. After that step you are ready to load the key with Putty Agent. If you don’t have it download pageant.exe from Putty website. Run pageant.exe and load the key. Now you can open Putty and login to your EC2 server.
If you plan to use the instance as a web server create a load balancer. One load balancer is free and it’s practical to use it. If for any reason you will have to stop your server IP address will change. It means you will have to change domain settings and wait 24h for propagation… not good. This is another thing I learned the hard way. It’s also better to have it ready in case you have to scale.
Click on “Load Balancers” on the left hand side navigation. It’s under “Network & Security” section. Click on “Create Load Balancer” button. It’s very easy setup. Just chose a name and go to step 3.

On this screen you have to specify which instances should be use with the load balancer. At this stage you should have only one item. Select it and click continue.

When you finish with configuration click on your load balancer. You will find notes which explain what is the best way to setup your domain.
Micro instance is good enough for a web server but might get slow with a database. For a database you might chose RDS. Go back to Amazon Web Services list by clicking on cube in the left top corner. Look for RDS under Database section. Click on DB Instances and then on Launch DB Instance button.

After selecting database engine pay attention to DB Instance Class settings. If you don’t want to pay for it select t1.db.micro and minimum storage size.
Using RDS is not require. You can fire another EC2 instance and set everything manual. The advantage of using RDS is free backups (to a certain level) and easy configuration.
I keep database and web server on the same EC2 instance. It wouldn’t survive the traffic it has without Varnish Cache. You can read about it here.
If you want to have multiple web servers you need to think how are you going to share use session. You can install memcached on each of your web servers or use ElastiCache.
ElastiCache is another service under Database section. There isn’t much more to say about it. Just be aware it’s there and you can use it.
This post covered basics of working with AWS however it should be enough to run a medium size website. Using Amazon is easy and fun. Number of features might be intimidating at the first glance but after few minutes it all start to make sense.
Some useful links to help you find out more about pricing and setups:
– AWS Free Usage Tier
– EC2 hardware configurations
– EC2 pricing
– RDS pricing

The good news is WordPress doesn’t have to be a speed demon. In most cases it’s just a CMS to produce static pages. If the content is static it doesn’t make any sense to waste CPU cycles on re-rendering the same HTML over and over again.
Currently I’m running this blog on Amazon EC2 Micro instance. It’s the smallest (and slowest) setup you can get from Amazon. The micro instance has 613 MB of RAM and a limited access to CPU. When I tried to benchmark it with the Apache Benchamark I got about 1 req/sec… and crashed database. Ten concurrent connections were enough to DoS my blog! Fifteen minutes later which was required to setup Varnish Cache the same hardware could handle 665 req/sec. During the test CPU got to 65% which means I reached broadband limits.
$ ab -c300 -n500 https://systemsarchitect.net/ Server Software: Apache/2.2.22 Server Hostname: systemsarchitect.net Server Port: 80 Document Path: / Document Length: 128174 bytes Concurrency Level: 300 Time taken for tests: 0.751 seconds Complete requests: 500 Failed requests: 0 Write errors: 0 Total transferred: 64310000 bytes HTML transferred: 64087000 bytes Requests per second: 665.85 [#/sec] (mean) Time per request: 450.555 [ms] (mean) Time per request: 1.502 [ms] (mean, across all concurrent requests) Transfer rate: 83633.83 [Kbytes/sec] received
So why to make a website fast? There are at least 3 reasons:
– It will survive sudden traffic spikes (so called Slashdot effect)
– better Google ranking
– according to Google’s research there is a correlation between website’s response time and consumed content. In other words the faster website is the higher chance for another click.
Varnish Cache is a web application accelerator also known as a caching HTTP reverse proxy. You install it in front of any server that speaks HTTP and configure it to cache the contents. Varnish Cache is really, really fast. It typically speeds up delivery with a factor of 300 – 1000x, depending on your architecture.
Varnish stands in front of a web server which means it will have to listen on port 80. By default this port it already taken by Apache. The first thing is to change configuration of your web server.
$ vim /etc/apache2/ports.conf
Change port 80 to 8080.
NameVirtualHost *:8080
Listen 8080
Listen 443
Listen 443
Edit virtual host settings.
$ vim /etc/apache2/sites-available/architect
Alter port from 80 to 8080.
Now install varnish. Depends on your distribution you might get different version of the software. This article is created for varnish 3.x.
$ apt-get install varnish $ varnishd -V varnishd (varnish-3.0.2 revision cbf1284) Copyright (c) 2006 Verdens Gang AS Copyright (c) 2006-2011 Varnish Software AS
Edit varnish settings and set port and cache size.
$ vim /etc/default/varnish
Memory on my server is limited so I use only 64 MB. Default value is 254 but quoter of that is enough for a small blog.
DAEMON_OPTS="-a :80
-T localhost:6082
-f /etc/varnish/default.vcl
-S /etc/varnish/secret
-s malloc,64m"
Edit varnish configuration.
$ vim /etc/varnish/default.vcl
Change the VCL script to
backend default {
.host = "127.0.0.1";
.port = "8080";
}
sub vcl_recv {
if (req.restarts == 0) {
if (req.http.x-forwarded-for) {
set req.http.X-Forwarded-For =
req.http.X-Forwarded-For + ", " + client.ip;
} else {
set req.http.X-Forwarded-For = client.ip;
}
}
if (req.request == "PURGE") {
if ( client.ip != "54.246.44.13") {
error 405 "Not allowed.";
}
return (lookup);
}
if (req.request != "GET" &&
req.request != "HEAD" &&
req.request != "PUT" &&
req.request != "POST" &&
req.request != "TRACE" &&
req.request != "OPTIONS" &&
req.request != "DELETE") {
return (pipe);
}
if (req.request != "GET" && req.request != "HEAD") {
return (pass);
}
if (!(req.url ~ "wp-(login|admin)") &&
!(req.url ~ "&preview=true" ) ) {
unset req.http.cookie;
}
if (req.http.Authorization || req.http.Cookie) {
return (pass);
}
return (lookup);
}
sub vcl_hit {
if (req.request == "PURGE") {
purge;
error 200 "Purged.";
}
return (deliver);
}
sub vcl_miss {
if (req.request == "PURGE") {
purge;
error 200 "Purged.";
}
return (fetch);
}
sub vcl_fetch {
if (!(req.url ~ "wp-(login|admin)")) {
unset beresp.http.set-cookie;
set beresp.ttl = 96h;
}
if (beresp.ttl <= 0s ||
beresp.http.Set-Cookie ||
beresp.http.Vary == "*") {
set beresp.ttl = 120 s;
return (hit_for_pass);
}
return (deliver);
}
You will have to change the IP 54.246.44.13 to your server’s address.
Everything is in place now so the last thing to do is restartng services.
$ sudo /etc/init.d/apache2 restart $ sudo /etc/init.d/varnish restart
To make sure caching is working run tail against all apache logs and refresh your website few times.
$ tail -f /var/log/apache2/*
First request will hit Apache server and you should see new entries in the log. Varnish will put all resources for that URL in cache. Every following request shouldn’t populate any new logs.
The VCL configuration makes Varnish cache every GET request for 96 hours. There is an exception for wp-login and wp-admin. Those are dynamic pages and it’s better not to cache them. Your visitors have no reason to go there anyway.
Varnish will cache everything for 96h. If you create a new post or edit an existing one your changes won’t be visible. Varnish doesn’t know something has changed and will continue serving stale content. You can restart the service to wipe all data.
$ /etc/init.d/varnish restart
It’s not very user friendly approach. It also clears more then it should. Don’t worry, it’s WordPress. There is plugin for everything. Install “Varnish HTTP Purge” extension. No configuration is required. Default.vcl file already handlers PURGE requests. Now you can visit your blog, open network tab in Firebug and enjoy response time below 200ms.
Varnish is an amazing peace of software with very powerful features. It can act as a load balancer, it can pull different parts of your website from different palaces (ESI) and if it can’t do something there might be an extension for that. There is nothing to wait for. Download it. Use it.
You might like to read


When you rent a server/instance to server websites you pay for broadband and computing power to process requests. It’s not about how impressive RAM/CPU figures are. The question is how many request per second can be handled and how long does it take.
The benchmark was performed with following software:
– WordPress – tested application.
– ab (apache benchmark) – measuring software
– APC (alternative php cache) – I wanted to benchmark computing power not hard drive I/O
WordPress site had 2 “Lorep Ipsum” posts (changing number of posts will change benchmark figures) with few categories, tags and an image. I benchmark each setup from the same remote host with 50 concurrent connections and performed 500 requests (ab -c 50 -n 500). Tested URL was homepage.
| setup | requests per sec | cost per hour |
|---|---|---|
| 4x small | 22.33 | 0.26 |
| 1x medium | 11.77 | 0.13 |
| 2x medium | 22.92 | 0.26 |
| 3x medium | 31.64 | 0.39 |
| 1x large | 22.73 | 0.26 |
| 1x High CPU – medium | 22.89 | 0.165 |
| 1x HIgh CPU – high | 70.24 | 0.66 |
The most striking conclusion from this tests is that 4 small instances gives as much power as 2 medium or 1 large. They also cost the same. Some solutions might benefit from distributed setup so when one instance falls there are 3 more. On the other hand large instance has 4 time more RAM which might be more appropriate for some extensive caching strategy.
It gets little bit more interesting with requests per second divided by cost per hour.
| setup | requests/cost |
|---|---|
| 4x small | 90.53 |
| 1x medium | 88.15 |
| 2x medium | 81.12 |
| 3x medium | 85.88 |
| 1x large | 87.42 |
| 1x HIGH CPU medium | 138.72 |
| 1x HIGH CPU high | 106.42 |
The “High CPU” group visibly stands out. When you need multiple web frontends it looks like the best choice is the “High CPU – medium” instance. It gives the best value for the money. At the moment of writing this article the instance comes with following parameters:
1.7 GiB of memory 5 EC2 Compute Units (2 virtual cores with 2.5 EC2 Compute Units each) 350 GB of instance storage 32-bit or 64-bit platform I/O Performance: Moderate EBS-Optimized Available: No API name: c1.medium
It’s worth to mention that “High CPU – High” offers High I/O performance. My WordPress benchmark couldn’t benefit from that because PHP code was cached in memory. I can imagine that for some type of applications it might be an important requirement.
Will Gloople move to AWS ecosystem? I don’t know. There are many other factors which need to be taken under consideration. Nevertheless it was fun to learn little bit more about Amazon and their pricing schema. EC2 instances look very similar and it’s tempting to skip testing and go for a bunch of small servers. This examples shows that sometimes it pays to do homework.

Chat is far more challenging because you not only have to handle simultaneous connections but also allow communications between processes. Inter process communication (IPC) has to be close to real time, synchronized and safe from racing condition.
Before I continue let me say the example I’m going to show won’t work on Windows. It use POSIX extension which is available only on Linux-like environments.
As previously you can download the code from GitHub and try it.
$ git clone https://github.com/lukaszkujawa/php-multithreaded-socket-server.git socketserver $ cd socketserver $ php server-broadcast.php $ Listening on 127.0.0.1:4444...
From different terminals
$ telnet 127.0.0.1 4444
To see how it works you need at least two telnet sessions. When a messages is typed on one of them it should be immediately broadcasted to the others.

SocketServerBroadcast (which extends SocketServer) is heart of the application and is handled by parent process. The Parent is responsible for listening for a new connections, maintaining list of active connections and sending broadcast on a child process request.
Client connections are handled by callback “onConnect()” in server-broadcast.php. When data is received an instance of SocketClientBroadcast wraps it into an array and sends it via pipe to the parent process. The code which actually sends the data is inside SocketServerBroadcast.
public function broadcast( Array $msg ) {
$msg['pid'] = posix_getpid();
$message = serialize( $msg );
$f = fopen(self::PIPENAME, 'w+');
if( !$f ) {
echo "ERROR: Can't open PIPE for writtingn";
return;
}
fwrite($f, $this->strlenInBytes($message) . $message );
fclose($f);
posix_kill($this->pid, SIGUSR1);
}
To tell the parent which child send a message a PID key is added to the message array. Pipe works like a file so the array has to be converted to a string. Serialiaze() is perfect for the job. The parent listening on the other side of the pipe is unable to figure out how long a message is going to be. The child has to tell him. In order to achieve that every first 4 bytes in every message are representing an integer. The integer carries a length of the message.
fwrite($f, $this->strlenInBytes($message) . $message );
Finally, when data is sent the child has to inform the parent there is a message for him.
posix_kill($this->pid, SIGUSR1);
Posix_kill() send a SIGUSR1 signal to $this->pid which holds the parent process id.
SocketServerBroadcast register SIGUSR1 in beforeServerLoop method.
protected function beforeServerLoop() {
parent::beforeServerLoop();
socket_set_nonblock( $this->sockServer );
pcntl_signal(SIGUSR1, array($this, 'handleProcess'), true);
}
It also set the socketServer to work in a nonblocking mode. By default socket_accept() waits for a new connection and is blocking process execution. When the nonblocking mode is on, socket_accept() checks is there any new connection at a certain moment. If there isn’t it throws a warning and continues execution.
protected function serverLoop() {
while( $this->_listenLoop ) {
if( ( $client = @socket_accept( $this->sockServer ) ) === false ) {
$info = array();
if( pcntl_sigtimedwait(array(SIGUSR1),$info,1) > 0 ) {
if( $info['signo'] == SIGUSR1 ) {
$this->handleProcess();
}
}
continue;
}
In the main loop the server check is there a connection and if not it wait 1 second for a SIGUSR1 signal. When signal is sent pcntl_sigtimedwait() returns immediately and $this->handleProcess() is executed.
public function handleProcess() {
$header = fread($this->pipe, 4);
$len = $this->bytesToInt( $header );
$message = unserialize( fread( $this->pipe, $len ) );
if( $message['type'] == 'msg' ) {
$client = $this->connections[ $message['pid'] ];
$msg = sprintf('[%s] (%d):%s', $client->getAddress(), $message['pid'], $message['data'] );
printf( "Broadcast: %s", $msg );
foreach( $this->connections as $pid => $conn ) {
if( $pid == $message['pid'] ) {
continue;
}
$conn->send( $msg );
}
}
else if( $message['type'] == 'disc' ) {
unset( $this->connections[ $message['pid'] ] );
}
}
Before the parent acquire a message from the pipe is has to know how long the message is. As you remember first 4 bytes hold the length.
$header = fread($this->pipe, 4); $len = $this->bytesToInt( $header );
Following code is straight forward. Read the actual message, unserialize and handle it.
That would be it. You can extend this example and create much complex application. Be cautious that the pipe communication strictly relies on [HEADER][MESSAGE] pattern. If for any reason header value will get incorrect the application will not recover. For a real live server I would suggest to implement a solution to mitigate header corruption.
